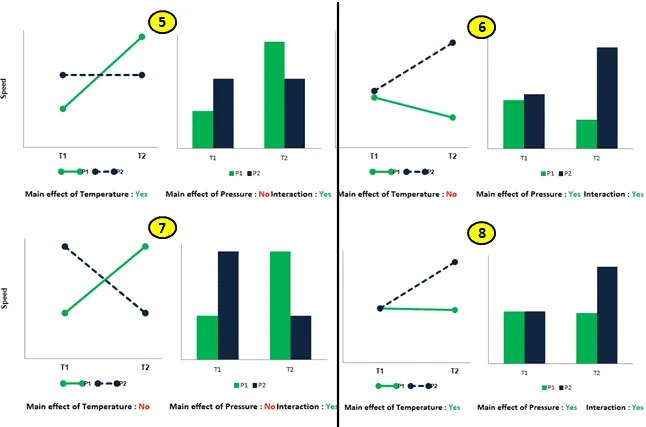
Testing for Interaction and Main Effect in Statistical Analysis with a Public Dataset
Learn how to test for main effects and interactions using Python's statsmodels with the public Tips dataset.
Regression vs. Classification: Understanding the Difference in Machine Learning
1. Introduction
In machine learning, tasks are broadly categorized into two types: regression and classification. These tasks differ not only in the type of output they predict but also in the models that are best suited to solve them. This post explains the key differences between regression and classification, and highlights models that work well with each.
2. What is Regression?
Regression is used when the goal is to predict a continuous output variable. This might involve forecasting stock prices, predicting house values, or estimating temperature changes.
Common Regression Models
- Linear Regression:
A simple model that assumes a linear relationship between input variables and the output. - Ridge and Lasso Regression:
Extensions of linear regression that incorporate regularization to prevent overfitting. - Decision Trees and Ensemble Methods (e.g., Random Forest, Gradient Boosting):
These can capture non-linear relationships and interactions between features.
3. What is Classification?
Classification is applied when the outcome is categorical. This means the model assigns inputs to one of several predefined classes. Use cases include spam detection, image recognition, and medical diagnosis.
Common Classification Models
- Logistic Regression:
Despite its name, logistic regression is used for binary classification by modeling probabilities. - Support Vector Machines (SVM):
Effective in high-dimensional spaces and useful when clear margins of separation exist. - Decision Trees and Ensemble Methods (e.g., Random Forest, XGBoost):
These can manage complex data distributions and interactions. - Neural Networks:
Suitable for tasks like image and speech recognition where patterns are highly non-linear.
4. Key Differences
| Aspect | Regression | Classification |
|---|---|---|
| Output Type | Continuous values (e.g., price, temperature) | Discrete categories (e.g., spam/ham, cat/dog) |
| Evaluation Metric | Mean Squared Error (MSE), R² score | Accuracy, Precision, Recall, F1-score |
| Decision Boundary | Not applicable; predicts numeric values | Establishes boundaries between classes |
| Use Cases | Forecasting, trend analysis | Object recognition, sentiment analysis, diagnostics |
5. Practical Example
Below is a simplified example contrasting regression and classification using scikit-learn.
5.1. Regression Example: Predicting House Prices
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load dataset (deprecated; for example purposes, assume similar structure)
data = load_boston()
X, y = data.data, data.target
# Split the dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a linear regression model
reg_model = LinearRegression()
reg_model.fit(X_train, y_train)
# Evaluate the model
y_pred = reg_model.predict(X_test)
print("Regression MSE:", mean_squared_error(y_test, y_pred))5.2. Classification Example: Predicting Iris Species
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Split the dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a logistic regression model
clf_model = LogisticRegression(max_iter=200)
clf_model.fit(X_train, y_train)
# Evaluate the model
y_pred = clf_model.predict(X_test)
print("Classification Accuracy:", accuracy_score(y_test, y_pred))6. Conclusion
Understanding whether your problem is a regression or classification task is key to selecting the appropriate model and evaluation metrics. Use regression techniques for continuous output prediction and classification methods when your output consists of distinct categories. Experiment with different models and tune hyperparameters to achieve optimal performance for your specific task.
Happy modeling!